4. Tietokantojen suunnittelu
4.1. Miksi tietokantojen suunnitteluun pitäisi kiinnittää huomiota?
Yhdysvaltalainen Michael J. Hernandez käsittelee mainiossa kirjassaan tietokantojen suunnittelua käytännössä. Hänen mukaansa tietokantojen suunnitteluun pitää kiinnittää huomiota siksi, ettei luultaisi että tietokantojen tekeminen on sitä, että istutaan tietokoneen ääreen ja tehdään tietokanta käyttämällä apuna monissa ohjelmissa olevia mallitietokantoja, velhoja tai eksperttejä. Hernandezin mukaan nämä sinänsä näppärät apuvlineet helpottavat tietokannan fyysistä tekemistä. Ne eivät kuitenkaan auta ymmärtämään tietokannan suunnittelun teoriaa, jonka ymmärtäminen on edellytys tehokkaalle tietokantasuunnittelulle.
E.F.Coddin 1970-luvun alussa esittämä relaatiotietokantamalli perustuu kahteen matematiikan haaraan: joukkoteoriaa ja ensimmäisen kertaluvun predikaattilogiikkaan. Relaatiotietokantojen taustalla on siis vankasti teoriaa, joka takaa sen että mallin mukaan suunnitellut tietokannat toimivat oikein. Ei ole kuitenkaan tarpeen opiskella korkeampaa matematiikkaa, jotta voisi tehdä hyvin suunniteltuja ja hyvin toimivia relaatiotietokantoja. Riittää, kun omaksuu hyvän suunnittelutavan.
Hyvän suunnittelumenetelmän opettelulla saavutetaan Hernandezin mukaan kolme merkittävää etua:
Hernandezin mukaan hyvälle tietokantasuunnittelulle voidaan asettaa joukko tavoitteita, joihin tulee päästä:
Mitä edellä olevat tavoitteet sitten tarkoittavat käytännössä?
Tuki tietojen hakemiselle
Tietokannan sanotaan olevan kattava, kun se sisältää kaikki ne tiedot, joita tietokantaa hyödyntävät järjestelmät ja mahdolliset ad-hoc - kyselyt tarvitsevat. Mutta onko tietokannan suunnittelussa mahdollista ottaa huomioon kaikki mahdolliset tarpeet? Ei luonnollisestikaan ole ja suunnittelussa tuleekin lähteä liikkeelle tilanteesta, jossa huomioidaan tyypillisimpien tiedonhakujen vaatimat tiedot.
Selkeys ja tehokkuus
Mitä yksinkertaisempi taulurakenne tietokannalla on, sitä helpompi sitä on käyttää. Tietokannan suunnittelussa hyvä nyrkkisääntö on: yksi asia taulua kohden.
Eheys
Tietokannan eheydellä tarkoitetaan tilannetta, jossa samaa tietoa ei toisteta tietokannassa tarpeettomasti ja jossa tietoon virheetöntä. Tähän päästään normalisoinnilla, josta myöhemmin lisää.
Liikesääntöjen tukeminen
Liikesäännöt tarkoittavat tietokantaan sisällytettyjä erilaisia rajoituksia ja ohjauksia, jotka vaikuttavat siihen miten tietokannan sisältämää tietoa voidaan käyttää. Liikesäännöt eivät välttämättä ole pysyviä, sillä kun organisaation toiminta muuttuu niin liikesäännötkin muuttuvat. Tämä johtuu siitä, että organisaation näkökulma tietoon muuttuu toiminnan muuttuessa.
Laajentaminen ja muokkaus
Tietokannan suunnittelussa tulee varautua tulevaisuuteen. Tietokannan rakenne tulee suunnitella sellaiseksi, että siihen tehtävät muutokset eivät ainakaan kovin suuresti vaikuta tietokantaa käyttävän sovellusohjelman rakenteen ja päinvastoin. Tietokantoja käyttävät sovellukset suunnitellaankin ikään kuin "kolmessa kerroksessa": pohjalla on itse tietokanta, sen päällä liiketoimintalogiikka ja päällimmäisenä käyttöliittymä. Tällä tavalla toimien saadaan tietokannasta mahdollisimman yleiskäyttöinen ja helposti eri asiakkaille monistettava: kaikilla asiakkailla on sama tietokantarakenne, asiakaskohtaiset muutokset hoidetaan käyttämällä säädettäviä parametreja.
4.4. Tietokantojen suunnitteluprosessi
Tietokantojen suunnitteluun voidaan soveltaa samoja suunnittelumenetelmiä kuin muuhunkin ohjelmointiin. Ja koska on kyse prosessista, on aivan välttämätöntä käydä joka kerta läpi prosessin kaikki vaiheet. Vain näin toimimalla varmistutaan siitä, että tietokanta on kunnolla suunniteltu.
Käytännössä tietokantojen suunnittelu on projektityötä, jonka onnistunut suorittaminen edellyttää valmiuksia projektityöskentelyyn. Työvälineiksi tarvitset lyijykynän, pyyhekumin ja ja ruutupaperia. Aluksi et tarvitse mitään tietokannan hallintajärjestelmää, sillä suunnittelun on oltava riippumatonta tietokannan toteutusteknologiasta.
Hernandez esittää kirjassaan tietokannan suunnitteluprosessin seuraavalla tavalla:
1. Tehtäväselostuksen ja tehtävän tavoitteiden määrittely
Tehtäväselostus kuvaa tietokannan tarkoituksen ja toimii tulevan suunnittelutyön perustana. On sanomattakin selvää, että kunnollista suunnittelutyötä ei voi tehdä, jos ei tiedä mitä pitäisi suunnitella. Tehtäväselostus on kirjallinen dokumentti, jonka laatimiseen osallistuvat tietokannan kehittäjä ja asiakkaan puolelta johtohenkilöstöä tarpeellinen määrä. Tehtävän tavoitteiden määrittely tarkentaa tehtäväselostusta. Myös tavoitteiden määrittely tehdään kirjallisesti. Tähän tehtävään osallistuvat edellä mainittujen lisäksi asiakkaan loppukäyttäjän edustajat. (Kirj. huom. Käytännössä tietokantojen suunnittelua varten perustetaan projekti, jonka johtoryhmä vastaa tehtäväselostuksen laatimisesta ja varsinainen projektiryhmä tekee tavoitemäärittelyn. Tulokset kirjataan projektisuunnitelmaan).
2. Nykyisen tietokannan analysointi
Jos suunnitellaan uutta tietokantaa olemassa olevan tilalle, on tärkeää analysoida nykyisen tietokannan toiminta. Jos taas tietokantaa ei ole olemassa, pitää analysoida se tapa, jolla tietoa kerätään ja käsitellään erilaisten kaavakkeiden ja lomakkeiden ja mahdollisesti jonkin tietokoneohjelman avulla. Pitää löytää vastaukset kysymyksiin:
- minkälaisia tietoja organisaatio käyttää?
- miten se käyttää näitä tietoja?
- miten se käsittelee ja ylläpitää näitä tietoja?
Näihin kysymyksiin saadut vastaukset muodostavat perussuuntaviivat uuden tietokantarakenteen luomista varten. Kysymyksiin saat vastaukset haastattelemalla organisaation johtoa ja tietokannan nykyisiä ja/tai tulevia käyttäjiä.
Kun analysoit olemassa olevaa tietokantaa, kannattaa muistaa että se voi olla huonosti suunniteltu ja siinä voi olla vaikka mitä virheitä. Älä siis koskaan ota olemassa olevaa tietokantaa suoraan uuden tietokannan pohjaksi.
Nykyisen tietokannan analysointi voidaan Hernandezin mukaan suorittaa kolmessa vaiheessa:
- tietojen keräystavan tutkiminen: selvitetään, millä tavoin (lomakkeilla, kortistoilla, ohjelmilla jne..) tietokantaan tallennettu tieto on kerätty
- tietojen esitystavan tutkiminen: selvitetään, millä tavoin tietoja nykyisin esitetään (tietokannan raportit, kuvaruutuesitykset, tekstiasiakirjat jne)
- käyttäjien ja johdon haastatteleminen: selvitetään, miten tietoja käytetään
Analyysin tulokset dokumentoidaan ja niitä käytetään myöhemmin pohjana uuden tietokantarakenteen suunnittelussa.
3. Tietorakenteiden luonti
Tässä vaiheessa luot tietokannan tietorakenteen edellisessä vaiheessa keräämiesi tietojen pohjalta. Määrittelet taulut, avaimet ja luot yksittäiset kentät. Välillä keskustelet tekemistäsi määrittelyistä asiakkaan kanssa ja teet muutoksia. Tietorakenteiden luonti etenee tällä tavalla iteratiivisesti, kierros kierrokselta tarkentuen. Dokumentoi jokainen kierros ja kaikki muutokset. Tässä vaiheessa voit jo testata suunnitelmasi toimivuutta toteutusalustaksi valitulla tietokannan hallintajärjestelmällä.
4. Taulujen välisten yhteyksien selvittäminen ja luominen
Taas kerran työtapana on käyttäjien haastattelu, sillä vain tietokannan käyttäjät voivat kunnolla tietää mitä tauluja tarvitaan missäkin tilanteessa. Muista dokumentoida tämäkin vaihe huolellisesti. Voit testata taulujen välisiä yhteyksiä
5. Liikesäännöt
Tietokannan suunnittelussa on otettava huomioon ne erilaiset säännöt ja rajoitukset, jotka vaikuttavat tietokantaa käyttävän organisaation tapaan käyttää tietoa. Nämä säännöt ja rajoitukset rakennetaan sisään tietokantaan niin sanotuiksi liikesäännöiksi. Taas kerran joudut haastattelemaan sekä organisaation johtoa ja tietokannan tulevia käyttäjiä. Ja muista dokumentointi.
6.Näkymien määrittely
Näkymillä tarkoitetaan erilaisia tapoja esittää tietokannan sisältämää tietoa. Käytännössä tämä tarkoittaa sitä, että jokainen tietokannan käyttäjä näkee tietokannasta vain ne tiedot, jotka on katsottu hänen kannaltaan oleellisiksi. Teknisesti ottaen näkymä pohjautuu yhteen tai useampaan tauluun ja on aina tietty osanen, yhdistelmä tai yhteenveto taulun tai taulujen sisällöstä.
7. Datan eheyden arviointi
Viimeisenä vaiheena Hernandezin esittämässä tietokantojen suunnitteluprosessissa on arvioida tietokannan rakennetta datan eheyden kannalta. Käytännössä tämä tarkoittaa sitä, että jokainen kenttä ja jokainen taulu tarkistetaan ja varmistutaan siitä, että kentät ja taulut ovat rakenteeltaan oikeat. Samin tarkistetaan taulujen väliset yhteydet. Saadut tulokset pitää luonnollisesti dokumentoida. Työtapana voit käyttää vielä kerran käyttäjien haastattelua ja tietenkin testitietokantaa, jolla teet erilaisia tiedonhakuja.
Edellisessä kappaleessa kuvatun suunnitteluprosessin yhteydessä korostettiin moneen kertaan, että käyttäjien antamat tiedot pitää dokumentoida. Useinkaan ei pelkkä sanallinen dokumentointi riitä. Tietokantojen suunnittelussa käytetäänkin usein apuna käsitteellistä mallintamista, joka on tietyn kaavan mukaan etenevä tapa kuvata tietokannan rakenne graafisesti ensin käsitetasolla ja sitten taulujen rakenteina. Käsitteellisen mallintamisen tuloksena syntyy kaksi dokumenttia, käsitemalli ja tietomalli.
Käsitemalli
Käsitemalli tehdään usein graafisena kaaviona. Malli koostuu kahdesta kaaviosta, käsitekaaviosta ja ER-kaaviosta. Ensiksi tehdään käsitekaavio. (Kirj. huom. Itse käytän eräänlaista mind mapping- eli miellekuvakarttamenetelmän sovellutusta, jonka olen ristinyt "sämpylätekniikaksi". Nimi tulee siitä, että kuvaan käsitteitä soikioilla, jotka ainakin jossain määrin muistuttavat muodoltaan sämpylää). Teitpä käsitemallin millä tavalla tahansa, niin keskeistä on löytää kuvattavat käsitteet. Eräs paljon käytetty keino on etsiä tehtäväkuvauksesta kaikki substantiivit ja muodostaa niiden avulla käsitemalli.
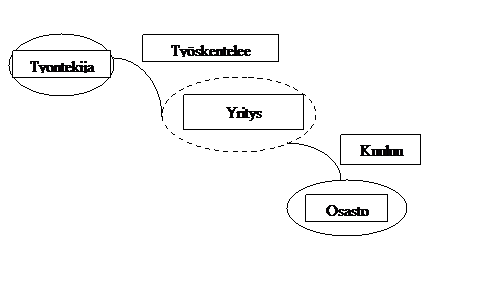
Peruskäsitteet -luvussa oli esimerkkinä yksinkertainen, kaksi taulua sisältävä tietokanta, jonka käsitekaavio voisi olla seuraavan kaltainen:
Käsitekaaviossa kuvataan jokainen käsite sekä käsitteiden liittyminen toisiinsa. Katkoviivalla kuvataan käsitteet, jotka eivät varsinaisesti kuulu suunniteltavaan tietokantaan (tässä Yritys) ja jotka jatkossa jätetän pois tarkastelusta.
Tästä jatketaan piirtämällä ER-kaavio, jossa jokainen käsitemallin käsite kuvataan yksityiskohtaisesti. ER-kaavion tai - mallin (Entity-Relationship - model), kumpaankin nimitystä käytetään kehitti alunperin Chen vuonna 1976. Sitä on sittemmin laajennettu ja parannettu paljon.
ER-kaavio koostuu useasta erilaisesta osasta, joita kuvataan tietyillä kuvioilla. Käytettävät kuviot ovat:
| Kuvio | Merkitys |
 |
Kohde, entiteetti, käsite, taulu |
| Suhde eli relaatio | |
| Ominaisuus eli attribuutti, jokin kohteesta tallennettava tieto, taulun jokin kenttä |
Esimerkiksi edellä kuvattu kahden taulun ER-kaavio voisi olla seuraavan kaltainen
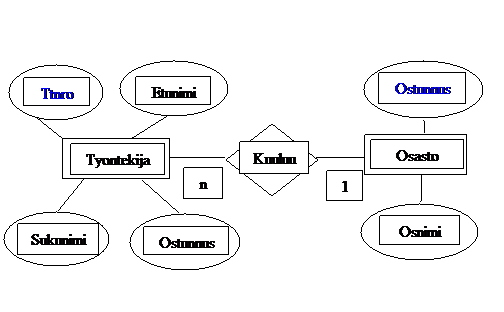
Tässä ER-kaaviossa on esimerkinomaisesti kuvattu kaksi käsitettä (Tyontekija ja Osasto), niille kummallekin muutama ominaisuus sekä vielä käsitteiden välinen yhteys. Sinisellä merkityt attribuutit ovat avainattribuutteja.
Tietomalli
Tietomallissa tarkennetaan käsitemallia ottamalla mukaan käytettävän tietokannan hallintajärjestelmän piirteitä ja määrittelemällä sen mukaan eri attribuuteille eli taulun kentille ominaisuuksia. Tärkeimmät ominaisuudet ovat kentän nimi, tietotyyppi, pituus sekä tieto siitä onko kyseessä avainkenttä. Tietomalli voidaan kuvata esimerkiksi näin
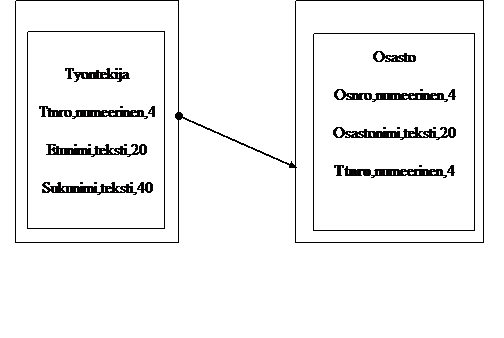
Käytännössä ER-kaavio ja tietomalli yhdistetään usein samaan kaavioon.
Oppimistehtävä 2. Täältä löydät pienen toimeksiannon. Tee sen pohjalta tehtäväselostus ja määrittele suunniteltavan tietokannan tavoitteet. Dokumentoi työsi Word-asiakirjana rtf-muotoon tallennettuna.
Oppimistehtävä 3. Jatka suunnittelutyötä tekemällä käsitemalli ja tietomalli. Dokumentointi kuten edellä.
Nyt on tullut aika ruveta tekemään itse tietokantaa. Edellä laadittu tietomalli itse asiassa kuvaa tietokannan rakenteen niin tarkasti, että voisimme istua tietokoneen ääreen ja luoda tietokannan. Sitä ennen on kuitenkin varmistuttava siitä, että kaikki on kunnossa. Suunnitelmamme pitää vielä kerran tarkistaa niin sanotun normalisoinnin avulla.
Normalisointi on menettelytapa, jolla pyritään vähentämään tietojen toistamista ja tästä aiheutuvia ongelmia tietojen lisäämisessä, poistamisessa ja päivityksessä. Normalisoinnilla lisätään taulurakenteiden selkeyttä, yhtenäisyyttä ja laajennettavuutta. Normalisointi perustuu niin sanottuihin normaalimuotoihin, joita on viisi kappaletta:
- ensimmäinen normaalimuoto
- toinen normaalimuoto
- kolmas normaalimuoto
- Boyce-Codd - normaalimuoto
- neljäs normaalimuoto
- viides normaalimuoto
Käytännössä vain kolmella ensimmäisellä normaalimuodolla on merkitystä, muut ovat teoreettisia lähestymistapoja. Normaalimuotojen syntymistä helpottaa tämän säännön noudattaminen:
- kohteen yhteyteen eli tauluun tallennetaan vain kohteeseen välittömästi liittyviä tietoja
- kunkin tiedon päivitys tapahtuu vain yhteen paikkaan
Ensimmäinen normaalimuoto
Määritelmä: taulu on ensimmäisessä normaalimuodossa, jos sen jokaisen attribuutin arvojoukko koostuu vain atomistisista arvoista. Tämä tarkoittaa, että taulun jokaisen tietueen jokainen kenttä sisältää vain yhden arvon, mutta ei listoja. Jokaisen kentän pitää sisältää vain yhden tyyppistä tietoa (tekstiä, numeerista tms.), mutta ei näitä sekaisin.
Katsotaanpa alla olevaa taulua. Onko se ensimmäisessä normaalimuodossa? (Esimerkki löytyy Tommi Lahtosen SQL-kirjasta)
| Tilausnro | Asiakasnro | Pvm | Tilaus |
| 1 | 1 | 1.1.2000 | 1 kiintolevy, 1 prosessori, 3 hiirtä |
| 2 | 2 | 2.1.2000 | 1 tietokone |
| 3 | 3 | 3.1.2000 | 5 näyttöä, 3 koteloa |
| 4 | 4 | 4.1.2000 | 2 näytönohjainta, 3 muistikampaa |
| 5 | 3 | 5.1.2000 | 1 digitaalikamera, 1 skanneri |
Äkkiseltään kaikki näyttäisi olevan hyvin, taulussahan on aivan selvästi asiakkaiden eri päivinä tekemiä tilauksia. Mutta jos yrittäisit tehdä tästä taulusta tuotekohtaista myyntiraporttia, niin tuskin onnistuisit. Taulu ei nimittäin ole ensimmäisessä normaalimuodossa, koska Tilaus-kentässä on useita arvoja yhdessä tietueessa.
Parannellaan taulua hieman lisäämällä siihen uusia sarakkeita eli kenttiä
| Tilausnro | Asiakasnro | Pvm | Lkm 1 | Tuote 1 | Lkm 2 | Tuote 2 | Lkm 3 | Tuote 3 |
| 1 | 1 | 1.1.2000 | 1 | Kiintolevy | 1 | Prosessori | 3 | Hiiri |
| 2 | 2 | 2.1.2000 | 1 | Tietokone | ||||
| 3 | 3 | 3.1.2000 | 5 | Näyttö | 3 | Kotelo | ||
| 4 | 4 | 4.1.2000 | 2 | Näytönohjain | 3 | Muistikampa | ||
| 5 | 3 | 5.1.2000 | 1 | Digikamera | 1 | Skanneri |
Relaatiomallin periaatteisiin kuuluu, että jokaisessa tietueessa on saman määrä kenttiä ja tässä ei niin ole. Tällainen rakenne hukkaa paljon tilaa. Mutta onneksi ongelma voidaan korjata käsittelemällä yhden tuotteen tilauksen jokaisella rivillä. Samalla taulu muuttuu ensimmäisen normaalimuodon mukaiseksi.
| Tilausnro | TilausTuote | Asiakasnro | Pvm | Lkm | Tuote |
| 1 | 1 | 1 | 1.1.2000 | 1 | Kiintolevy |
| 1 | 2 | 1 | 1.1.2000 | 1 | Prosessori |
| 1 | 3 | 1 | 1.1.2000 | 3 | Hiiri |
| 2 | 1 | 2 | 2.1.2000 | 1 | Tietokone |
| 3 | 1 | 3 | 3.1.2000 | 5 | Näyttö |
| 3 | 2 | 3 | 3.1.2000 | 3 | Kotelo |
| 4 | 1 | 4 | 4.1.2000 | 2 | Näytönohjain |
| 4 | 2 | 4 | 4.1.2000 | 3 | Muistikampa |
| 5 | 1 | 3 | 5.1.2000 | 1 | Digitaalikamera |
| 5 | 2 | 3 | 5.1.2000 | 1 | Skanneri |
Toinen normaalimuoto
Määritelmä: taulu on toisessa normaalimuodossa, jos se on ensimmäisessä normaalimuodossa ja sen jokainen attribuutti, joka ei esiinny avainehdokkaassa, on täysin riippuva tästä avainehdokkaasta. Tämä tarkoittaa, että taulun jokaisen kentän, joka ei ole avainehdokas (pääavain) täytyy suoraan liittyä taulun avaimeen. Tauluun pitää siis tallentaa vain sellaista tietoa, joka liittyy yhteen ja samaan asiaan.
Jatketaan esimerkin käsittelyä ja lisätään tauluun tuoteID-kenttä. Onko taulu nyt toisessa normaalimuodossa?
| Tilausnro | TilausTuote | Asiakasnro | Pvm | Lkm | TuoteID | Tuote |
| 1 | 1 | 1 | 1.1.2000 | 1 | 1 | Kiintolevy |
| 1 | 2 | 1 | 1.1.2000 | 1 | 2 | Prosessori |
| 1 | 3 | 1 | 1.1.2000 | 3 | 3 | Hiiri |
| 2 | 1 | 2 | 2.1.2000 | 1 | 4 | Tietokone |
| 3 | 1 | 3 | 3.1.2000 | 5 | 5 | Näyttö |
| 3 | 2 | 3 | 3.1.2000 | 3 | 6 | Kotelo |
| 4 | 1 | 4 | 4.1.2000 | 2 | 7 | Näytönohjain |
| 4 | 2 | 4 | 4.1.2000 | 3 | 8 | Muistikampa |
| 5 | 1 | 3 | 5.1.2000 | 1 | 9 | Digitaalikamera |
| 5 | 2 | 3 | 5.1.2000 | 1 | 10 | Skanneri |
Taulun pääavain muodostuu tässä tapauksessa kahdesta kentästä, Tilausnro- ja TilausTuote - kentistä. Kaikkien muiden kenttien pitäisi riippua suoraan tästä avaimesta, jotta toinen normaalimuoto toteutuisi. Nyt se ei toteudu, koska AsiakasNro- ja Pvm-kentät ovat riippuvaisia vain tilausnumerosta, mutta eivät koko avaimesta.
Saamme esimerkin taulun toiseen normaalimuotoon jakamalla sen kahdeksi tauluksi. Nythän sama taulu sisältää tietoja sekä tilauksista (kentät Tilausnro, Asiakasnro ja Pvm) että tilattavista tuotteista (kentät TilausTuote, Lkm, TuoteID ja Tuote)
| Tilausnro | Asiakasnro | Pvm |
| 1 | 1 | 1.1.2000 |
| 2 | 2 | 2.1.2000 |
| 3 | 3 | 3.1.2000 |
| 4 | 4 | 4.1.2000 |
| 5 | 3 | 5.1.2000 |
| Tilausnro | TilausTuote | Lkm | TuoteID | Tuote |
| 1 | 1 | 1 | 1 | Kiintolevy |
| 1 | 2 | 1 | 2 | Prosessori |
| 1 | 3 | 3 | 3 | Hiiri |
| 2 | 1 | 1 | 4 | Tietokone |
| 3 | 1 | 5 | 5 | Näyttö |
| 3 | 2 | 3 | 6 | Kotelo |
| 4 | 1 | 2 | 7 | Näytönohjain |
| 4 | 2 | 3 | 8 | Muistikampa |
| 5 | 1 | 1 | 9 | Digitaalikamera |
| 5 | 2 | 1 | 10 | Skanneri |
Kolmas normaalimuoto
Määritelmä: taulu on kolmannessa normaalimuodossa, jos se on toisessa normaalimuodossa ja kaikki kentät, jotka eivät kuulu avaimeen ovat itsenäisiä ja riippumattomia muista kentistä.
Esimerkkimme taulu ei ole kolmannessa normaalimuodossa, koska TuoteID- ja Tuote-kentät riippuvat toisistaan. Samaan tauluun on tallennettu sekä tilaustietoja että tuotetietoja, joten taulu täytyy vielä jakaa kahteen osaan.
| TuoteID | Tuote |
| 1 | Kiintolevy |
| 2 | Prosessori |
| 3 | Hiiri |
| 4 | Tietokone |
| 5 | Näyttö |
| 6 | Kotelo |
| 7 | Näytönohjain |
| 8 | Muistikampa |
| 9 | Digitaalikamera |
| 10 | Skanneri |
| Tilausnro | TilausTuote | Lkm | TuoteID |
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 2 |
| 1 | 3 | 3 | 3 |
| 2 | 1 | 1 | 4 |
| 3 | 1 | 5 | 5 |
| 3 | 2 | 3 | 6 |
| 4 | 1 | 2 | 7 |
| 4 | 2 | 3 | 8 |
| 5 | 1 | 1 | 9 |
| 5 | 2 | 1 | 10 |
Nyt meillä on kaksi taulua, joissa kummassakin on vain yhteen asiaan liittyvää tietoa ja eri tietojen päivitykset tehdään vain yhteen paikkaan.
Oppimistehtävä 4. Laadi tietokannan taulut tehtävän 3 mallien mukaisesti ja suorita tauluille normalisointi.